UnitedANT: A Multimodal Deep Learning Framework for Predicting Financial Risk from Acoustic, Numeric, and Textual Cues in Earnings Conference Calls
Sen Yan, Bao Yang, and Fang Hui
In Proceedings of the 30th WORKSHOP ON INFORMATION TECHNOLOGIES AND SYSTEMS , WITS-2020, Dec 2020
Earnings conference calls have been recently recognized as significant information events to the market due to its less constrained fashion and direct interaction between managers and analysts. However, it is a non-trivial task to fully exploit the information contained in these conference calls due to its multimodality. To tackle this problem, we develop a general multimodal deep learning framework called UnitedANT (A, N, T stands for Acoustic, Numeric, and Textual information respectively) which could simultaneously leverage acoustic, numeric, and textual information of conference calls for predicting corporate financial risk. Empirical results on a real-world dataset of S&P 500 companies demonstrate the superiority of our proposed method over competitive baselines from the extant literature. Our ablation study presents evidence that all three modalities are useful for financial risk prediction, and the exclusion of any one or two of them will lead to a drop in model performance.
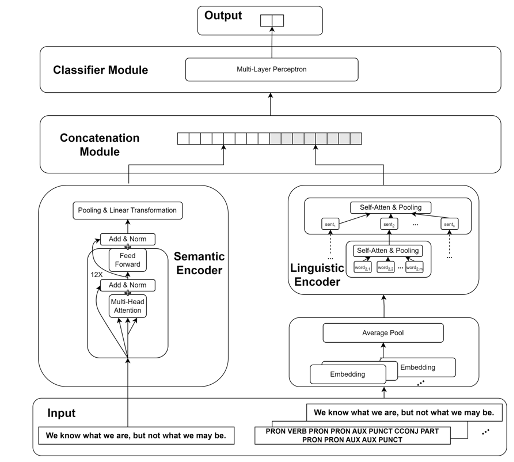 An explainable framework for assisting the detection of AI-generated textual contentDecision Support Systems, 2025
An explainable framework for assisting the detection of AI-generated textual contentDecision Support Systems, 2025
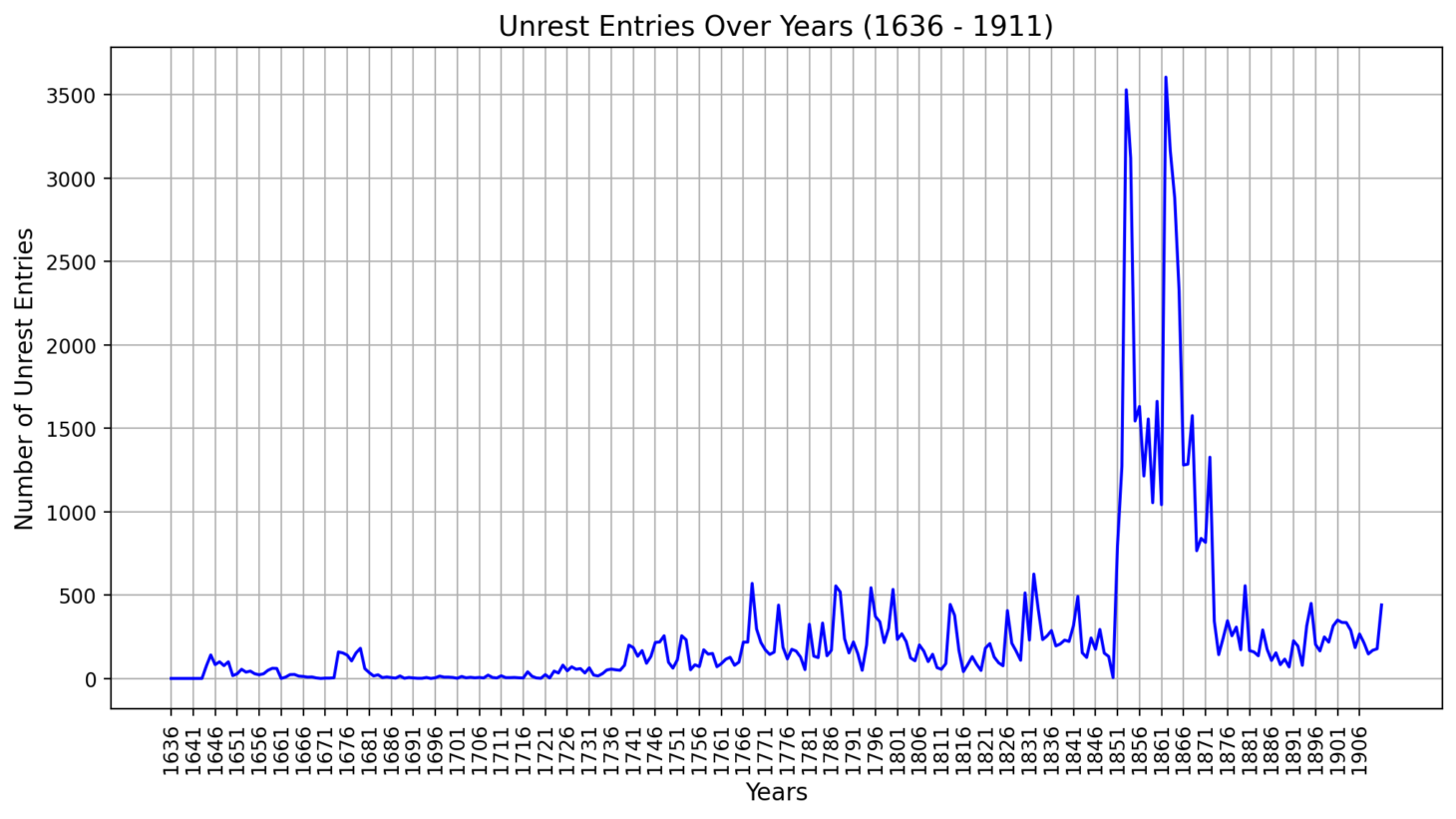 Mining Chinese Historical Sources At Scale: A Machine Learning-Approach to Qing State CapacityDemo Website Link , Dec 2024
Mining Chinese Historical Sources At Scale: A Machine Learning-Approach to Qing State CapacityDemo Website Link , Dec 2024



